摘要:本文詳細介紹了如何基于 CMDB(Configuration Management Database)實現全鏈路故障排查拓撲的構建與應用,并探討了 CMDB 在未來智能化發展中的潛力。文章適用于運維工程師、值班故障處理人員,以及 CMDB 配置經理和管理員。
涉及關鍵詞: CMDB 治理,故障排查拓撲, CMDB 自動采集技術、AI在 CMDB 的應用
01.引言:為什么 CMDB 的全鏈路拓撲建設如此重要?
在現代 IT 運維管理中,復雜的系統架構和多樣化的應用場景使得故障排查變得極具挑戰性。對于運維工程師、值班故障處理人員,以及 CMDB 配置經理和管理員來說,快速、準確地定位故障根因是保障業務連續性和用戶體驗的關鍵。然而,隨著 IT 基礎設施的日益復雜,單純依賴傳統的監控和管理工具已無法滿足當代運維要求。1)什么是 CMDB ?
CMDB(Configuration Management Database)是一種用于存儲 IT 基礎架構中所有配置項(CI)及其關系的數據倉庫。在 CMDB 中,每個 CI 都可以是一個實體(例如服務器、交換機、安全設備等),或者是一個邏輯資源(例如虛擬機、應用服務、存儲卷等)。CMDB 的作用不僅在于收集和管理這些 CI 的狀態信息,更重要的是了解和記錄它們之間的相互關系,以及這些關系在業務系統中的位置和作用。
2)全鏈路故障排查拓撲的意義
構建一個全面、健壯的全鏈路故障排查拓撲,對于提升 IT 運維效率至關重要。通過完善的拓撲結構,我們能夠:
- 快速響應與定位故障:通過直觀的拓撲圖可以快速定位故障點,節省排查時間。
- 全面掌控關鍵資源:全面了解不同資源,包括前端負載均衡、應用、主機、云平臺、物理服務器、安全設備(如防火墻、IPS、IDS)和存儲系統之間的依賴關系,確保各個環節互動良好。
- 提升運維自動化水平:實現對資源依賴關系的自動化管理,減少人工干預,提高運維效率和準確性。
- 降低業務中斷風險:通過預防性維護和及時故障處理,降低業務系統的停機時間和用戶受到影響的風險。
通過本文的介紹,運維人員、配置經理和管理員將能夠更好地理解和使用 CMDB 全鏈路拓撲,提升 IT 服務管理水平,實現業務穩定性和持續性保障,本文具體內容下:
- 拓撲建設思路:從整體規劃到逐層細化,結合業務需求設計全鏈路拓撲結構。
- CI 模型的建立:定義各類 CI 的屬性和字段,以最小化原則精簡設計,確保重要信息的全面覆蓋。
- CI 關系的建立:設置關鍵資源之間的依賴關系,確保拓撲圖的準確性和可讀性。
- CI 屬性和關系的采集:介紹數據采集的技巧與工具,重點闡述關系采集的方法與技術。
- 故障排查的應用示例:通過具體案例演示如何利用拓撲定位和解決實際運維中的故障,提升運維效率。
02.拓撲建設思路
在構建完善的 CMDB 全鏈路故障排查拓撲的過程中,需遵循一定的建設思路,以確保拓撲結構科學合理、數據準確全面,并具備動態更新的能力。本文將重點介紹拓撲建設的統一入口視角、自頂向下與自底向上結合的建設方式,以及構建過程中的設計準則。
1)統一入口視角:以業務為中心
拓撲建設的首要思路是以業務為中心展開。業務需求是系統運維的核心,從業務視角出發,可以更直觀地體現各個 IT 資源對業務運行的支持程度。
- 業務需求分解:從企業的關鍵業務出發,逐層分解與其相關的各類 IT 資源。這些資源可能包括了前端的負載均衡設備、應用服務、運行應用的主機、底層的云平臺和物理服務器、網絡設備(如防火墻、IPS/IDS等),以及存儲系統。
- 關聯關系分析:把每一個業務需求逐一分析,確定支撐這些需求的設備和資源之間的直接與間接關系。例如,某一關鍵業務應用可能依賴于多個數據庫,而這些數據庫又分別運行在不同的虛擬機和物理服務器上。
通過這樣的方式,我們能夠構建出一幅詳盡的業務資源依賴關系圖。這張圖不僅展示了關鍵業務的組成和運作機制,也能幫助我們在故障發生時,快速確認業務所依賴的具體資源以及它們之間的關聯關系。
2)自頂向下與自底向上結合的建設方式
在具體操作中,可以采用自頂向下與自底向上相結合的方式進行拓撲建設。
- 自頂向下(Top-down):從業務流程和系統架構圖入手,確定各個業務需求所涉及的關鍵節點和依賴關系。逐層細化:從高層業務邏輯到中層服務組件,最終細化到底層的基礎設施設備(如服務器、網絡設備等)。
- 自底向上(Bottom-up):從物理和邏輯基礎架構出發,逐步識別和采集各個具體配置項(CI)的信息。匯總形成各個資源節點的屬性和狀態數據,建立這些節點之間的依賴和互動關系。
結合方式:
- 統籌關聯:通過自頂向下的方法構建出大框架,再結合自底向上的數據采集,確保每個環節和節點都得到了覆蓋和連接。
- 雙向驗證:頂層設計提供了一個總體規劃,而底層數據的采集和反饋,則確保了設計的合理性與實用性。兩者彼此驗證,確保拓撲結構的完整性和準確性。
3)構建拓撲時的設計準則
在拓撲建設過程中,需遵循以下設計準則,確保拓撲結構的高效性和易用性:
- 數據完整性:確保拓撲結構覆蓋所有關鍵節點和關系。避免遺漏重要的組件和聯接。方法:定期審查和更新 CMDB 中的 CI,保證數據的實時性和準確性。
- 數據最小化:只采集并管理必要的字段,避免數據冗余和信息泛濫。方法:制定采集策略,初期只采集關鍵字段,確保每個字段都有明確用途。逐步優化字段模型。
- 動態更新能力:保證拓撲數據與實際狀態保持同步,適應環境動態變化。方法:通過自動化腳本和智能化工具,實現對 CI 及其關系的實時監測和更新。
- 易讀性與可視化:構建清晰易讀的拓撲圖,輔助可視化工具幫助快速理解和運維。方法:采用專業的可視化工具,將復雜的關系以圖形化形式呈現,增強直觀感。
- 安全與合規:在數據采集和展示過程中,依照企業的安全和合規要求,保護敏感信息。方法:制定并實施數據治理和安全策略,防止數據泄露和誤用。
通過以上準則的指導,我們能夠構建出一個既全面詳細,又高效實用的 CMDB 全鏈路故障排查拓撲,為運維管理和故障排查提供堅實保障。在接下來的章節中,我們將細化這些步驟,詳細講解 CI 模型的建立、關系的確立、屬性和關系的采集方法,并結合實際案例進行應用示范。
03.CI 模型的建立
CMDB 的核心在于將 IT 環境中所有的設備、系統和虛擬資源抽象成配置項(Configuration Item,簡稱 CI),并在此基礎上進行統一管理。CI 模型的建立是構建 CMDB 的第一步,關系到數據的規范、拓撲的結構化,以及后續故障排查的效率。在這一部分,我們將詳細說明 CI 是什么,如何遵循最小化原則設計精簡高效的數據模型,并通過典型場景示例展示關鍵 CI 的設計模板。
1)什么是 Configuration Item(CI)
配置項(CI) 是 CMDB 中的最基本構成單元,代表 IT 系統中的實體或邏輯對象。CI 不僅包含資源的自身屬性,還與其他 CI 建立關聯,形成全鏈路的模型。因此,一個優秀的 CI 一定要具備以下兩個特點:
- 獨立性:作為一個獨立對象,CI 能夠被單獨管理或操作。例如,一臺服務器,一個負載均衡設備,或者一個存儲卷。
- 關聯性:CI 并非孤立存在,而是與其他 CI 形成復雜的依賴或支持關系。例如,應用服務依賴于主機,主機運行在虛擬機上,而虛擬機可能托管在某個云平臺上。
通過準確地建模 CI,我們可以清晰呈現 IT 系統中設備和資源的具體角色,并為全鏈路拓撲的建立奠定基礎。
2)CI 模型設計的最小化原則
在構建 CI 模型時,需遵循“最小化原則”,即只記錄必要的字段和屬性,確保數據的簡潔性和高效性。過于復雜或冗余的模型不僅會增加維護成本,還可能導致 CMDB 系統性能下降,降低實用性。
(1)最小化原則的具體方法:
- 識別關鍵字段:基于系統管理和故障排查需求,設計出對目標明確、對故障定位至關重要的字段。例如,一個主機的核心字段包括主機名、IP 地址、CPU 配置等,而背景顏色或外殼材料這類無關字段可以剔除。
- 避免不必要的冗余:相同的信息不要重復存儲,盡量通過關系模型來引用。例如,不需要在每個應用服務的 CI 中重復存儲主機信息,而是通過主機與應用服務的關聯關系動態獲取。
(2)字段設計的示例:
以下是符合最小化原則的字段設計模板:
1. 主機:
- 必要字段:主機名、IP 地址、操作系統、CPU 核數、內存大小。
- 非必要字段(剔除):生產日期、物理尺寸。
2. 網絡設備(如交換機、防火墻):
- 必要字段:設備名、IP、端口數、廠商。
- 非必要字段(剔除):外殼顏色、銷售代理。
通過科學定義字段,我們能夠減少不必要的數據冗余,同時確保故障定位所需的關鍵信息持續可用。
3)典型場景的CI模型模板
在 IT 系統中,不同類型的資源和設備對應不同的 CI 模型。以下是針對常見場景的幾個模板設計:
(1)負載均衡設備
用途:負責分發前端業務流量。
字段設計:

(2)應用服務
用途:分發業務邏輯并處理用戶請求。
字段設計:
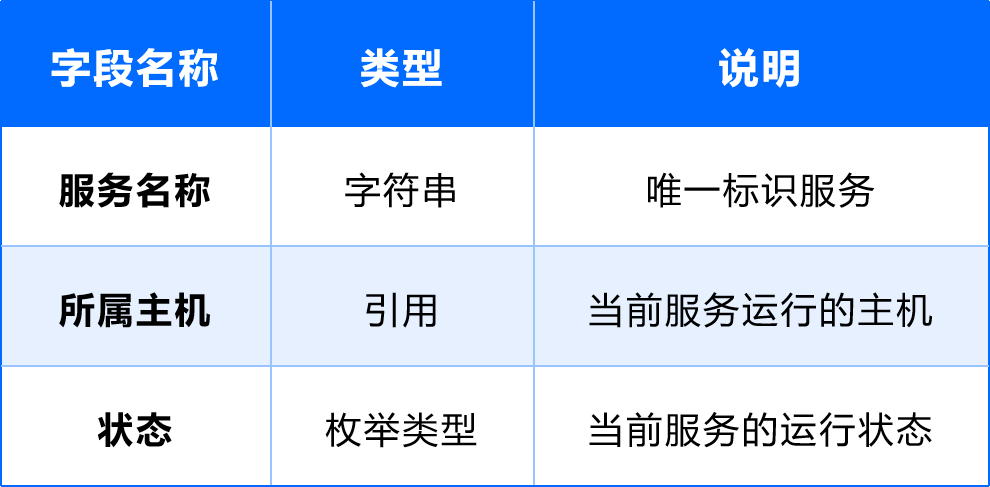
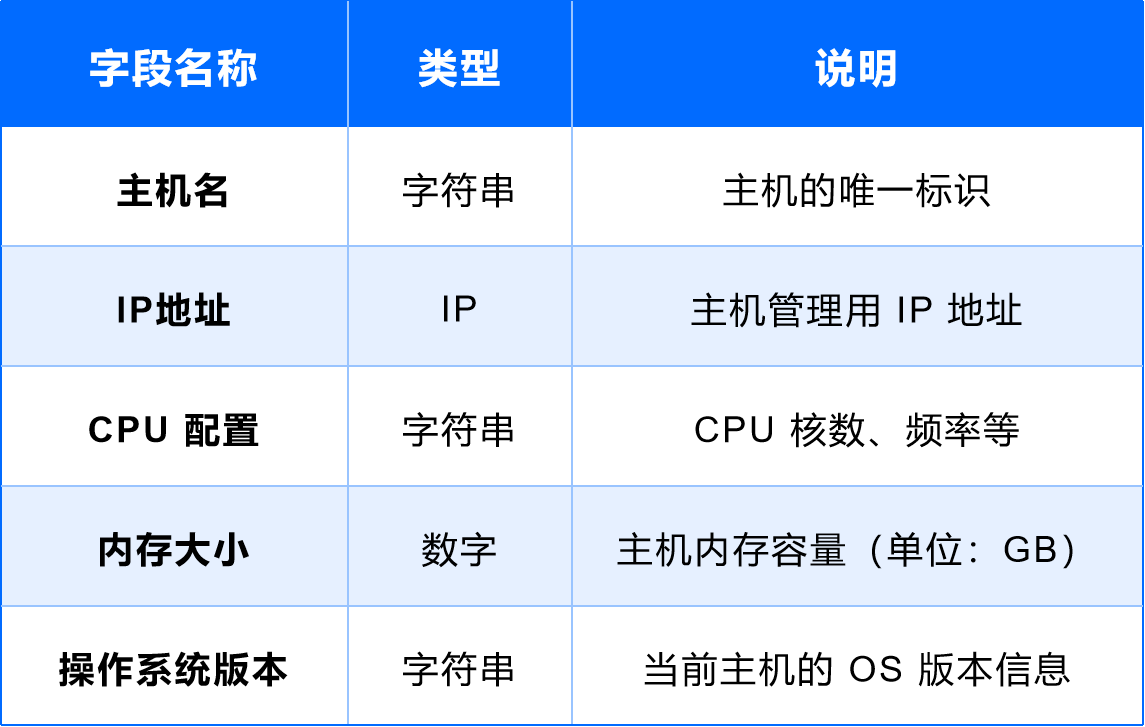
(3)主機
用途:承載基礎軟件及應用運行。
字段設計:
(4)防火墻 / IPS / IDS 等安全設備
用途:保護系統安全,檢測和防御攻擊。
字段設計:

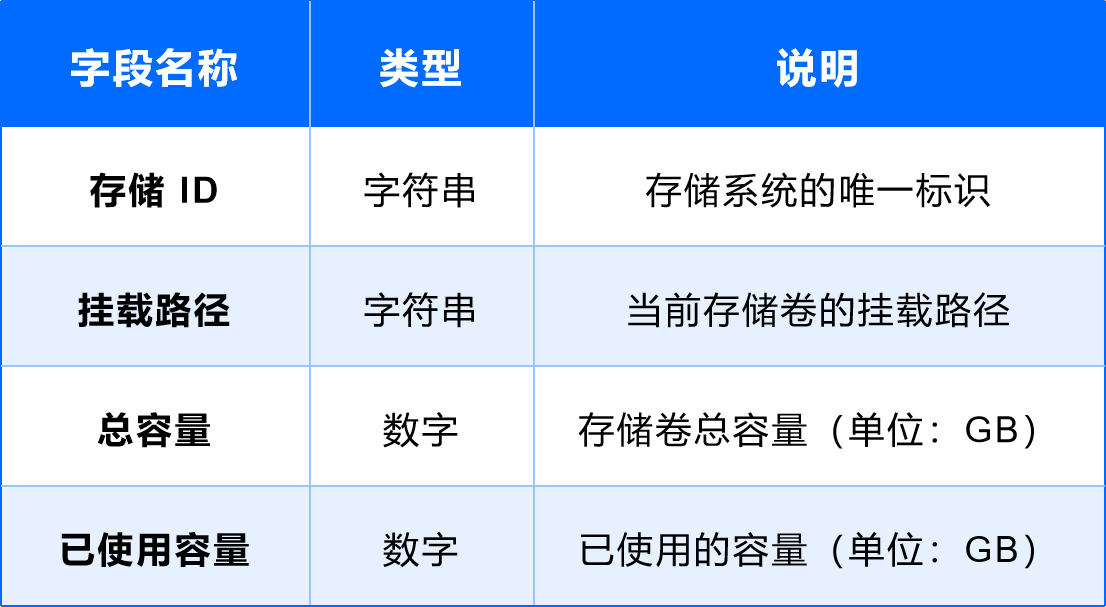
(5)存儲系統
用途:提供數據存儲服務。
字段設計:
(6)交換機
用途:提供網絡連接和數據包轉發。
字段設計:

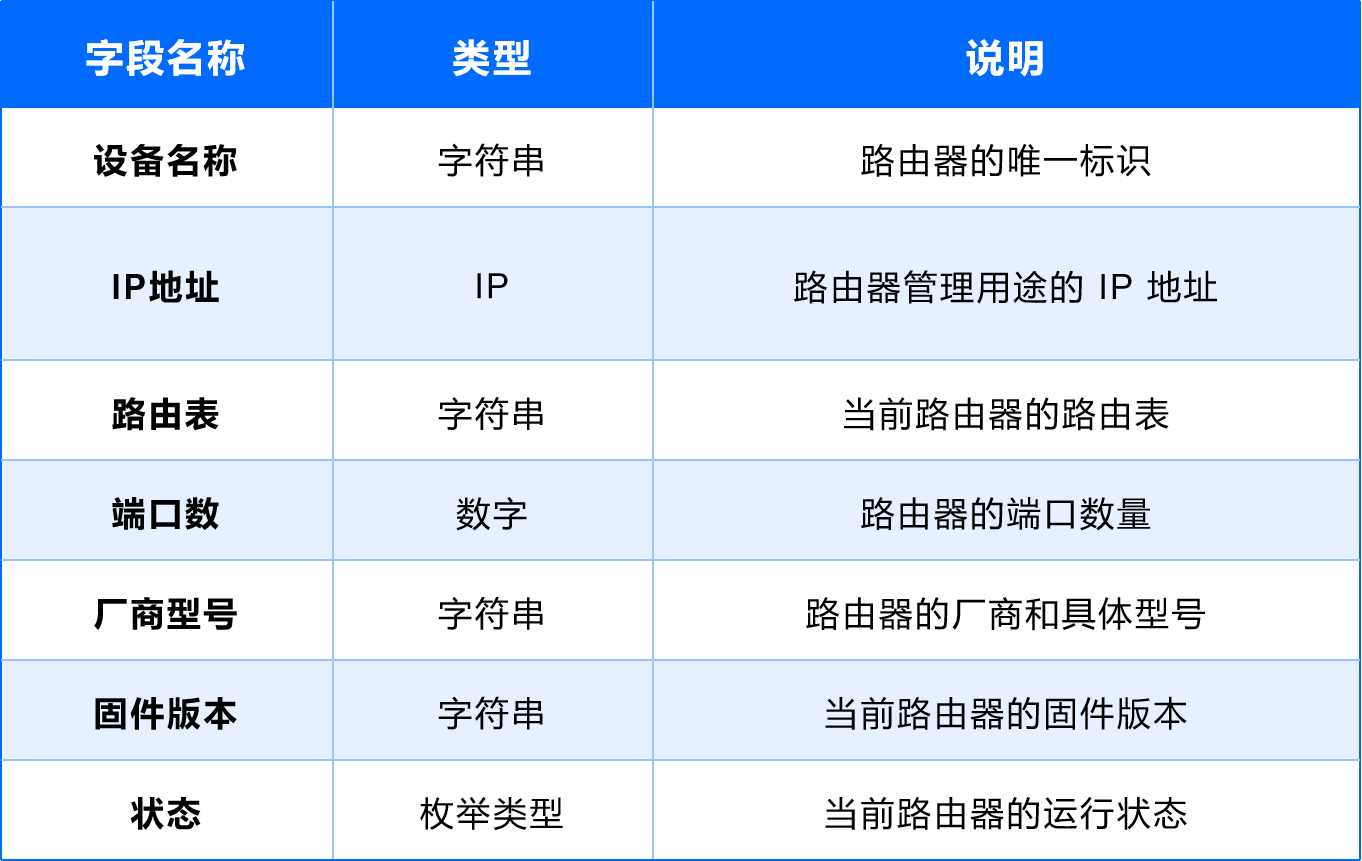
(7)路由器
用途:提供網絡路由和路徑選擇。
字段設計:
CI 模型的建立是 CMDB 拓撲建設的基礎步驟。在設計 CI 的過程中,需始終遵循最小化原則,確保字段設計精簡而高效,同時兼顧實際運維需求。通過針對不同場景設計的 CI 模板,我們能夠實現 IT 環境的結構化管理,為下一步的 CI 關系設計和全鏈路故障排查奠定良好基礎。
在下一章中,我們將繼續深入,講解如何基于這些 CI 模型建立起資源之間的關系,以形成真正的全鏈路拓撲圖。
04.CI 關系的建立
CI 的屬性定義能夠幫助我們清晰地描述每一項 IT 資源,但僅僅依靠單一的 CI 信息是不足以支持復雜 IT 系統的故障定位。全鏈路故障排查的核心,是依賴于各個 CI 之間的關系建模。通過精準定義和捕獲這些關系,我們可以構建一張全面的故障排查拓撲圖,實現從業務到底層設備的全鏈路可視化。
在本章中,我們將介紹 CI 之間關系在拓撲中的重要性、關系類型的分類與設計原則,并提供一系列典型的關系建模示例。
1)關系在拓撲中的重要性
每個 IT 系統的資源和組件,并不是孤立運行的,幾乎所有的資源都依賴于彼此共同協作。如果拓撲結構缺乏準確的關系建模,就可能導致以下風險:
- 故障定位模糊:某個應用故障背后可能有多種原因,例如網絡中斷、主機宕機或存儲異常。如果關系不明晰,可能會導致故障排查耗費大量時間。
- 維護復雜度增加:當系統規模擴展時,不了解資源間的依賴關系會導致部署和變更風險劇增。
基于這些問題,定義 CI 關系是構建 CMDB 拓撲的關鍵環節。通過合理的關系建模,我們可以:
- 快速明確“誰依賴誰”;
- 構建資源間的調用與傳遞鏈路;
- 識別不同子系統之間的潛在影響。
2)關系類型的設計
CMDB 的 CI 關系可以通過多種方式定義,在故障排查的場景下,建議劃分為以下幾種通用類型:
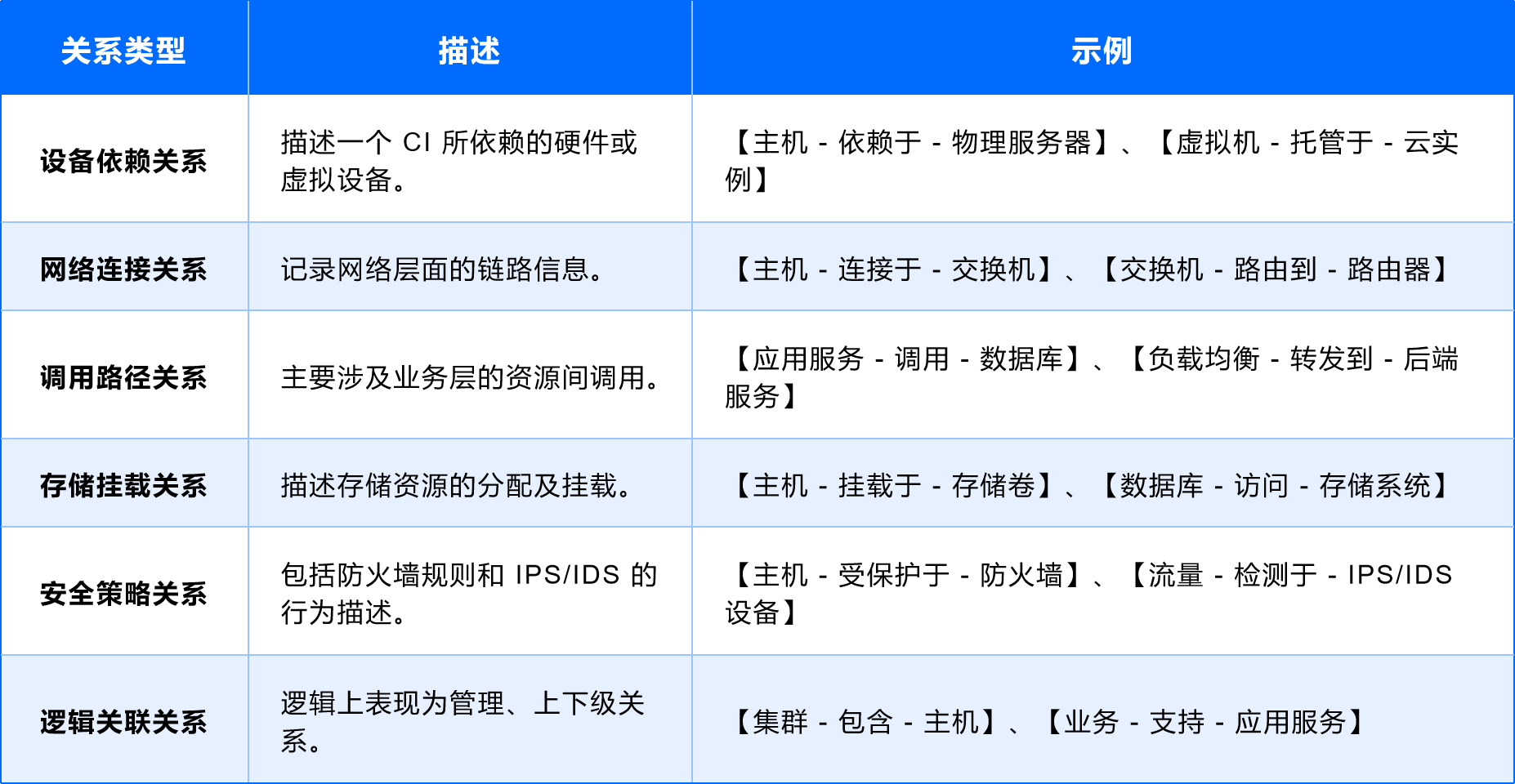
3)典型關系建模示例
以下是針對用戶常見場景的關系建模示例,更直觀地說明各種關鍵關系的設計。
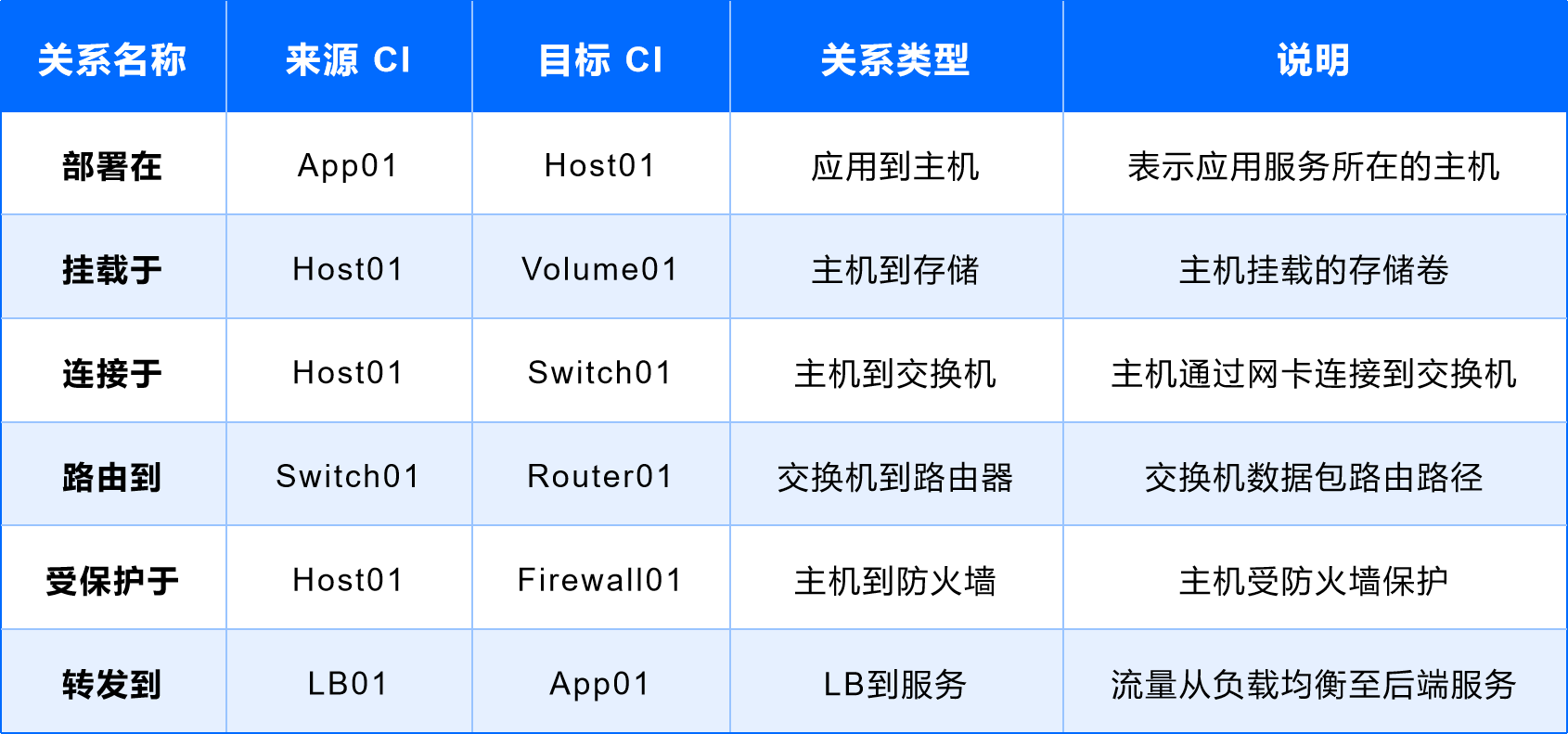
(1)應用服務與主機
- 關系類型:應用服務 - 部署在 - 主機
- 示例解讀:如某業務應用 App01 部署在主機 Host01 上,則通過這段關系,可以快速定位支撐應用運行的主機資源。
- 邏輯關系:App01 (來源 CI) 部署在 Host01 (目標 CI)
- 關系類型:主機 - 連接于 - 交換機
- 示例解讀:主機 Host01 通過網卡綁定到交換機 Switch01 的某一端口,可用于定位網絡鏈路故障。
- 邏輯關系:Host01 (來源 CI) 連接于 Switch01 (目標 CI)
- 關系類型:主機 - 掛載于 - 存儲卷
- 示例解讀:主機 Host01 與存儲卷 Volume01 之間建立了一組掛載關系。通過此關系可以快速定位存儲性能問題帶來的影響。
- 邏輯關系:Host01 (來源 CI) 掛載于 Volume01 (目標 CI)
- 關系類型:交換機 - 路由到 - 路由器
- 示例解讀:交換機 Switch01 將流量路徑路由到路由器 Router01,從而完成網絡通路的建立。
- 邏輯關系:Switch01 (來源 CI) 路由到 Router01 (目標 CI)
- 關系類型:業務或主機流量 - 檢測于 - 防火墻
- 示例解讀:業務流量通過防火墻 Firewall01 進行過濾,涉及訪問控制和安全策略。
- 邏輯關系:APP01、Host01 (來源 CI) 檢測于 Firewall01 (目標 CI)
- 關系類型:負載均衡 - 轉發到 - 應用服務
- 示例解讀:負載均衡設備 LB01 負責將外部流量分發到后端應用 App01。
- 邏輯關系:LB01 (來源 CI) 轉發到 App01 (目標 CI)
CI 關系的建立是 CMDB 中實現全鏈路管理的核心環節。關系的類型需要根據具體場景和運維目標進行劃分,以確保“誰依賴誰”“誰影響誰”清晰明了。通過合理設計關系模型和實現動態更新能力,我們可以構建一個結構清晰、實時準確的故障排查拓撲,為解決復雜故障提供支持。
接下來,我們將繼續討論如何通過工具和技術手段采集這些關系及其屬性,使拓撲建設更高效、更動態地反映實際狀態。
05.CI 屬性和關系的采集
創建了 CI 模型和關系模型之后,接下來的重要任務是如何準確、高效地采集這些 CI 的屬性和關系。采集數據不僅要保證準確性,還需要覆蓋全鏈路的實時動態變化,以確保 CMDB 中的數據始終與實際狀態保持一致。
1)數據采集的核心原則
- 準確性:確保采集的數據真實可靠,這是 CMDB 的基礎要求。錯誤或陳舊的數據將導致拓撲圖失效,進而影響故障排查和系統管理。
- 動態性:IT 環境是動態變化的,采集數據必須能夠及時反映資源和關系的變化,以保持與實際情況同步。
- 全面性:數據采集應覆蓋所有關鍵的 CI 和關系,避免任何遺漏,做到全鏈路清晰可查。
- 安全性:采集過程中必須遵循企業的安全策略,避免數據泄漏和未授權訪問。
2)CI 屬性采集
CI 屬性數據可以通過多種方式采集,以下是常用的幾種方法:(1)Agent-based 采集
通過在主機或設備上部署采集 Agent 實時獲取配置和狀態數據。
- 工具示例:藍鯨 Agent ,通過配置發現工具下發插件進行周期性采集。
- 優點:實時性高,能獲取詳細的指標和狀態信息。
通過標準化協議(如 SNMP、SSH)或系統 API 獲取數據,不需要在設備上安裝采集工具。
- 工具示例:SNMP 采集工具、第三方 API 腳本,通過藍鯨 Agent 在作業機上執行對應采集命令。
- 優點:不需要額外的 Agent 部署,降低入侵風險。
- 示例命令:
(3)日志和事件數據采集
通過采集系統日志和事件日志數據,獲取 CI 的狀態和變更情況。
- 工具示例:通過藍鯨 Agent 進行日志采集,并用采集插件做日志清洗,結構化。
- 優點:可以集成豐富的日志分析能力,有助于故障根因分析。部分數據難以通過 API 獲取的可以從日志里面提煉,是一個有力的補充數據源。
3)CI 關系的采集
相比于屬性數據,關系數據的采集通常更為復雜,需要系統化的工具和方法。以下是幾種常見的關系采集技術及其具體示例。(1)網絡掃描與鏈路檢測
通過自動化網絡掃描工具,識別各網絡設備之間的鏈路關系。
- 工具示例:Nmap、Netdisco。
- 優點:能全面掃描網絡設備,自動識別鏈路關系。
- 示例命令:
nmap -sP 192.168.0.0/24
(2)API 數據采集
通過各系統提供的 API 接口,獲取相關系統及服務間的調用和依賴關系。- 工具示例:curl、Postman、Python requests 庫。
- 優點:能夠直接調取系統數據,靈活可擴展。
- 示例命令:
http://application/api/resource/list
(3)主機 Agent 采集
通過在主機上部署采集 Agent,實時獲取配置、依賴關系和運行狀態數據,包括主機與其上部署的數據庫、中間件的依賴關系。- 工具示例:藍鯨 Agent ,通過配置發現工具下發插件進行周期性采集。
- 優點:實時性強:能夠持續采集主機相關的運行時信息。依賴精確性:自動發現主機與數據庫、中間件的依賴關系。可擴展性:可將采集到的數據發送到 CMDB 或監控系統用于后續分析。
(4)虛擬化/云平臺命令采集
通過虛擬化平臺(如 vCenter、Kubernetes)或云平臺(如 AWS、Azure)的原生命令接口,獲取虛擬資源與物理資源的關系數據。- 工具示例:govc(vCenter)、kubectl(Kubernetes)。
- 優點:能夠全面管理和監控虛擬化和云環境中的資源。
- 示例命令:
govc vm.info -json -vm <vm-name>
# 使用 kubectl 獲取 Kubernetes 節點信息
kubectl get nodes
(5)服務發現與鏈路追蹤
用于微服務架構的服務發現與鏈路追蹤系統,自動維護服務間的依賴關系和調用路徑。- 工具示例:Consul 、APM 工具如鯨眼 APM 。
- 優點:專為微服務架構設計,自動化程度高。
- 示例命令:
consul agent -dev
4)關系采集案例
以下表格全面展示了不同類型關系的采集方法、使用工具、具體采集命令及命令執行位置,確保實現全鏈路拓撲的建立。

06.CMDB拓撲在故障排查中的應用示例
在這一章,我們將以具體案例演示如何充分利用 CMDB 全鏈路故障排查拓撲,在復雜的 IT 環境中快速定位故障根因并高效解決問題。這些示例涵蓋了從應用層到物理層的各種常見故障場景。
1)示例一:應用服務不可用
故障描述:某一關鍵業務應用服務發生 502 錯誤,用戶無法訪問應用服務。
排查步驟:
(1)檢查負載均衡狀態:查看負載均衡設備的健康檢查狀態。
- 命令:curl http://lb/api/health-checks
- 如果負載均衡健康,則表示請求已成功發送到后端服務器
- 使用 CI 關系:應用服務 - 部署在 - 主機
- 確認實際運行狀態。
- 命令:curl http://app/api/status
- 目標主機信息可以通過 CMDB 獲得。
ssh user@host01
top # 查看實時系統資源使用情況
df -h # 檢查磁盤使用情況
(4)檢查詢主機網絡鏈路:確認主機與交換機之間的連接是否正常。
- 使用 Nmap 檢查內部網絡狀態。
- 命令:
(5)檢查應用調用路徑:查看應用服務是否成功調用了后端數據庫。
- 使用 CI 關系:應用服務 - 調用 - 數據庫
- 命令:curl http://app/api/db-status
2)示例二:網絡性能問題
故障描述:某業務網絡流量中斷或出現大量丟包。
排查步驟:
(1)通過 CMDB 確認該網絡鏈路上的相關對象。
(2)確認主機與交換機的連接狀態:檢查主要業務主機的網絡連接狀況,確認是否存在斷網或連接異常。
ssh user@host01
ifconfig # 查看網絡配置及連接狀態
ping 192.168.0.1 # 測試與交換機的連接
(3)檢查交換機到路由器鏈路:使用 Cisco Discovery Protocol (CDP) 或 LLDP 工具檢查交換機與路由器的連接健康狀況。
ssh user@switch01
show cdp neighbors detail # 或 show lldp neighbors detail
(4)檢測云平臺的網絡鏈路:如果主機托管于云平臺,使用云平臺 API 查詢虛擬網絡是否正常。
curl http://cloud/api/vm-network-status
(5)檢查防火墻策略:查看防火墻是否在相關流量中施加了限制或有新的策略變動。
- 命令:curl http://firewall/api/policies
snmpwalk -v2c -c public 192.168.0.1
(7)最終確認:結合以上信息找出網絡鏈路中的具體問題環節,是否交換機端口丟包、鏈路中斷還是防火墻策略導致網絡性能降低。
3)示例三:存儲系統性能瓶頸
故障描述:某業務系統日志顯示 IO 性能下降,導致應用響應時間變長。
排查步驟:
(1)確定受影響主機和應用:通過 CMDB 確認相關應用和主機。使用 CI 關系:應用服務 - 部署在 - 主機
(2)檢查主機磁盤 IO 狀況:登錄受影響的主機,檢查磁盤 IO 的具體情況。
ssh user@host01
iostat -x # 查看磁盤 IO 性能
(3)確認存儲接口和路徑:使用 CMDB 信息,查找主機掛載的存儲卷。
- 使用 CI 關系:主機 - 掛載于 - 存儲卷
- 命令:ssh user@host01 "lsblk"
ssh user@storage
sancli -list volumes -volume Volume01
(5)檢查存儲網絡路徑:確認存儲路徑上各節點(如交換機、SAN)是否存在性能瓶頸。匯總網絡鏈路和存儲鏈路的具體表現。
(6)最終確認:通過以上步驟,確定存儲系統性能下降的具體原因,是由于主機 IO 高峰,SAN 網絡瓶頸還是存儲設備的問題。
通過這些具體的故障排查案例,我們展示了如何利用 CMDB 全鏈路故障排查拓撲,在復雜 IT 環境中快速、準確地定位故障,提升運維效率。接下來的章節將討論 CMDB 的未來發展方向及其在智能運維中的廣泛應用。
07.總結與展望
1)總結
通過本文的介紹,我們完整地展示了如何基于 CMDB 建立全鏈路故障排查拓撲。從拓撲建設的基本思路到實際關系建模,再到具體的采集技術和實際應用示例,主要涵蓋以下幾個方面:
(1)拓撲建設思路:
- 從以業務為中心的視角出發,梳理 IT 環境中關鍵資源的依賴關系。
- 結合自頂向下的邏輯規劃和自底向上的數據采集方法,確保業務與底層設備的關聯完整清晰。
- 基于最小化原則設計 CI 模型,保證字段簡潔且實用。
- 模型覆蓋了負載均衡器、應用服務、主機、存儲系統、網絡設備(如交換機、路由器、防火墻、IPS、IDS)等在內的 IT 核心設施。
- 定義并建立 CI 之間關鍵關系,包括部署、網絡連接、業務依賴、存儲掛載、安全防護等。
- 基于關系建模實現故障排查中的“誰依賴誰”“誰影響誰”的邏輯鏈條。
(5)實際應用示例 :通過實際的故障排查場景(如應用服務不可用、網絡性能問題、存儲系統性能瓶頸),展示了如何利用 CMDB 拓撲實現快速、精確的根因分析。
- 提供了對整個 IT 環境的全鏈可見性。
- 加快了問題根因分析速度。
- 支持了動態環境中的持續更新和拓撲展現。
2)CMDB的智能化未來發展
隨著 IT 基礎設施的持續演進,CMDB 面臨的挑戰也在逐步加大,尤其是在云原生、微服務和邊緣計算環境中,傳統的 CMDB 系統因數據更新緩慢、關系定義復雜等局限,難以準確支撐快速變化的 IT 環境。然而,隨著大數據、人工智能(AI)的融合,CMDB 的潛在能力將被進一步釋放。以下從數據采集治理和數據消費兩個方向展開討論。
(1)CMDB 數據采集治理
1. 動態化與實時更新能力
- 目標:解決傳統 CMDB 數據更新緩慢、難以反映動態環境變化的問題。
- 解決方案:通過集成實時監控工具(如 Prometheus、Zabbix)和自動化采集工具(如 vCenter SDK、Kubernetes 原生接口),CMDB 可以自動感知資源上線、配置變更、狀態異常等動態事件。
- 效果或示例:實現對資源變化的實時響應。確保 CMDB 數據的實時性與環境同步。
- 目標:減少人工配置資源關系的工作量,提高依賴關系發現的準確性。
- 解決方案:利用機器學習和數據挖掘技術,自動發現資源之間的隱藏依賴及潛在關系。例如,通過聚類算法分析日志數據和網絡流量路徑,或通過時間序列模型分析資源性能波動與故障模式。
- 效果或示例:自動更新資源拓撲,減少人工操作。動態優化資源依賴關系,提高運維效率。
- 目標:提高數據質量,確保 CMDB 數據準確、一致。
- 解決方案:利用大模型的自然語言處理能力,自動檢測和清理 CMDB 數據中的錯誤和冗余。
- 效果或示例:清除重復數據、修復配置錯誤。
- 目標:識別并修正潛在的資源依賴關系,提高 CMDB 數據的縱深度。
- 解決方案:通過大模型分析歷史數據和配置,自動補充或推測尚未顯式定義的依賴關系。
- 效果或示例:推理潛在的跨區域網絡依賴。
- 目標:解決云原生架構的彈性伸縮、動態調度和多云部署帶來的數據采集復雜性問題。
- 解決方案:通過整合 Kubernetes API、OpenStack API 等云原生工具,實時更新云平臺資源,并實現以下能力:快速發現業務 Pod 的運行節點并反映到 CMDB 。在多云場景下,統一展示資源跨平臺的調用和依賴關系(如混合云環境中的主機與存儲)。
- 效果或示例:消除云原生復雜性帶來的數據孤島問題,構建云平臺資源的統一視圖。
1. 與 AIOps 的深度集成
- 目標:通過結合大數據分析和智能算法,提升故障檢測、影響評估和自動化響應的效率。
- 解決方案:AIOps 利用 CMDB 提供的全量配置數據和拓撲關系,進行智能化故障預測和根因分析。
- 效果或示例:提前預測資源瓶頸:如主機 CPU 長期高負載。智能根因定位:快速確定故障原因,并動態評估業務影響范圍。
- 目標:提升拓撲圖的可交互性和直觀性,讓運維人員更直觀地理解資源關系,快速排查問題。
- 解決方案:動態生成可交互的拓撲圖,支持多層級鏈路鉆取和基于業務流的分析視圖。
- 效果或示例:集成 3D 動態拓撲視圖,結合 Grafana 等工具展示系統健康狀況及變化趨勢。提供拓撲模擬功能,支持 "What If" 場景分析,例如模擬某節點故障后的業務影響。
- 目標:提高交互效率,使運維人員以自然語言查詢和獲取 CMDB 數據。
- 解決方案:基于大模型構建自然語言接口,例如,“告訴我主機 Host01 上運行的所有應用服務。”
- 效果或示例:通過問答窗口用自然語言對話直接給出查詢和統計結果。
- 目標:根據 CMDB 數據和運維場景提供個性化操作建議,提高運維效率和準確性。
- 解決方案:大模型基于當前數據給出擴容建議或優化策略。
- 效果或示例:根據主機 CPU 使用歷史,推薦增加資源。
- 目標:提高問題解決的自動化程度,減少人工干預。
- 解決方案:大模型結合 CMDB 數據,生成故障處理方案。
- 效果或示例:從日志中發現異常信息,基于CI關聯的工單解決方案自動生成恢復命令。
相關文章推薦
嘉為藍鯨CPack制品管理平臺:聯邦倉庫——助力跨團隊、跨地域、跨組織的制品資產協作

 2025-08-29
2025-08-29
查看詳細


嘉為藍鯨CMeas研發效能洞察平臺:一鍵保存你的專屬查詢儀表板
2025-08-29
查看詳細
嘉為藍鯨WeOps數據庫監控新范式:以專業監控視圖,賦能高效運維管理
2025-08-29
查看詳細
Jira國產化替代:從合規到價值,嘉為藍鯨DevOps敏捷協同平臺的破局之道
2025-08-29
查看詳細
嘉為藍鯨CCI持續集成平臺:掌控CI/CD全流程,流水線Stage準入讓部署更可靠
2025-08-22
查看詳細
嘉為藍鯨CMeas研發效能洞察平臺:研發效能周報,自動推送領導郵箱
2025-08-22
查看詳細







